
Can Increasing Input Dimensionality Improve Deep Reinforcement Learning?
Published in ICML, 2020
State representation learning (SRL) focuses on representation learning where learned features are in low dimension. Conventional wisdom suggests that the lower the dimensionality of the state vector, the faster and better RL algorithms will learn. However, while probably correct, this reasoning likely applies to the intrinsic dimensionality of the state. An interesting question is whether RL problems with intrinsically low-dimensional state can benefit by intentionally increasing its dimensionality? This paper explores this question empirically, using several representative RL tasks and state-of-the-art RL algorithms (PPO, TD3 and SAC).
Additionally, we borrow motivation from the fact that larger networks generally allow better solution as they increase the search space of possible solutions. Since the state representation is an intermediate variable of processing just like the hidden units, it is reasonable to expect that high-dimensional representations of state might improve the expressive power of the neural networks used in RL agents. Based on this idea, we propose OFENet: an Online Feature Extractor Network that constructs and uses high-dimensional representations of observations and actions, which are learned in a online fashion (i.e., along with the RL policy).
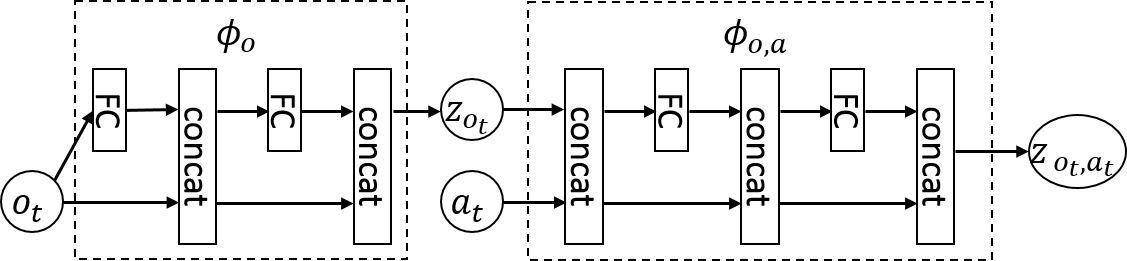
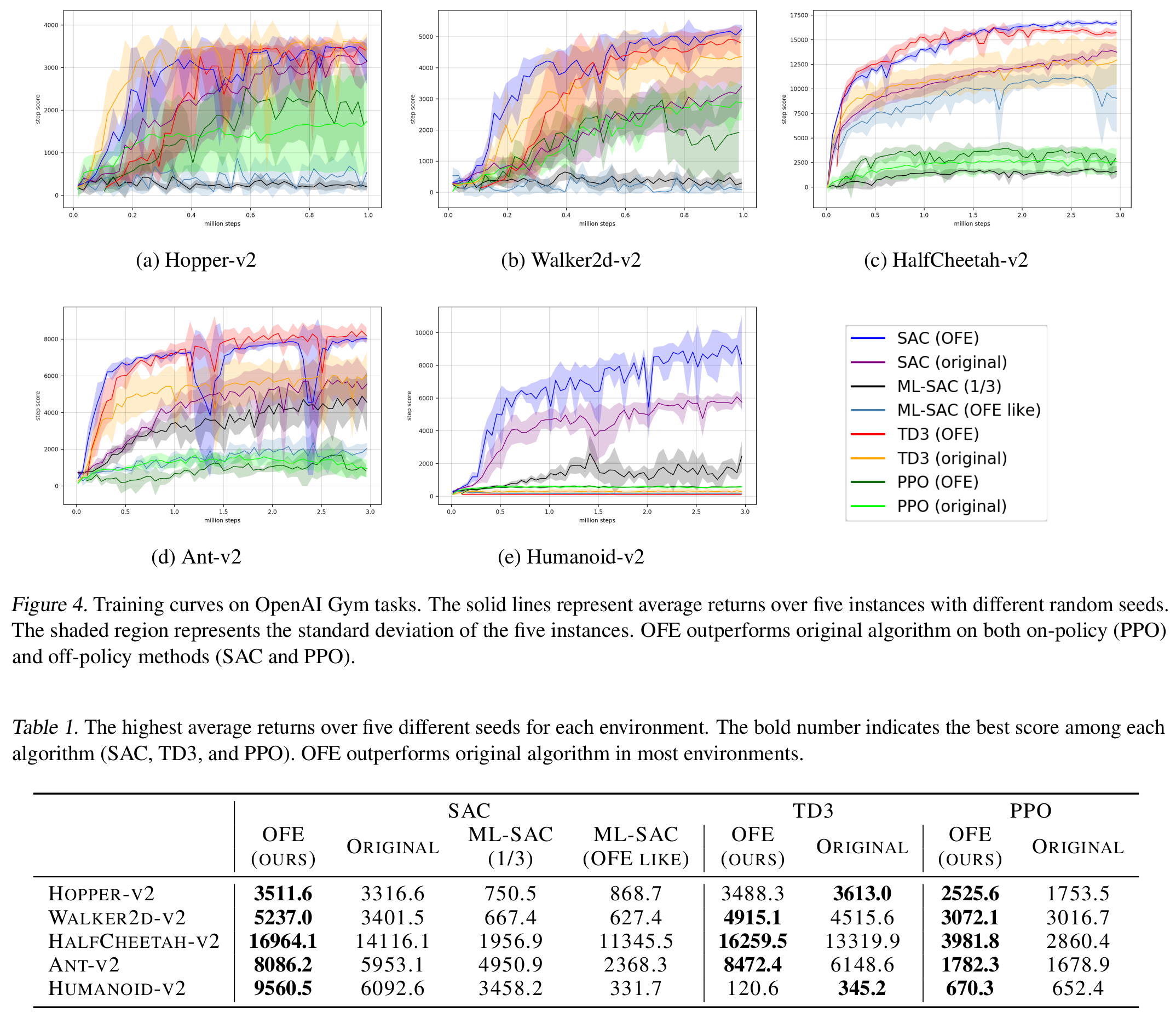
OFENet learns the mappings $z_{o_t}=\phi_o(o_t)$ and $z_{o_t,a_t}=\phi_{o,a}(o_t,a_t)$, which have parameters $\theta_{\phi_o}, \theta_{\phi_{o,a}}$ by using an auxiliary task whose goal is to predict the next observation from the current observation and action. The input to an RL agent is the learned futures $z_{o_t}$ and $z_{o_t,a_t}$, instead of original observations $o_t$ and actions $a_t$. Below figure and table shows the results. OFENet improves both sample efficiency and final performance.
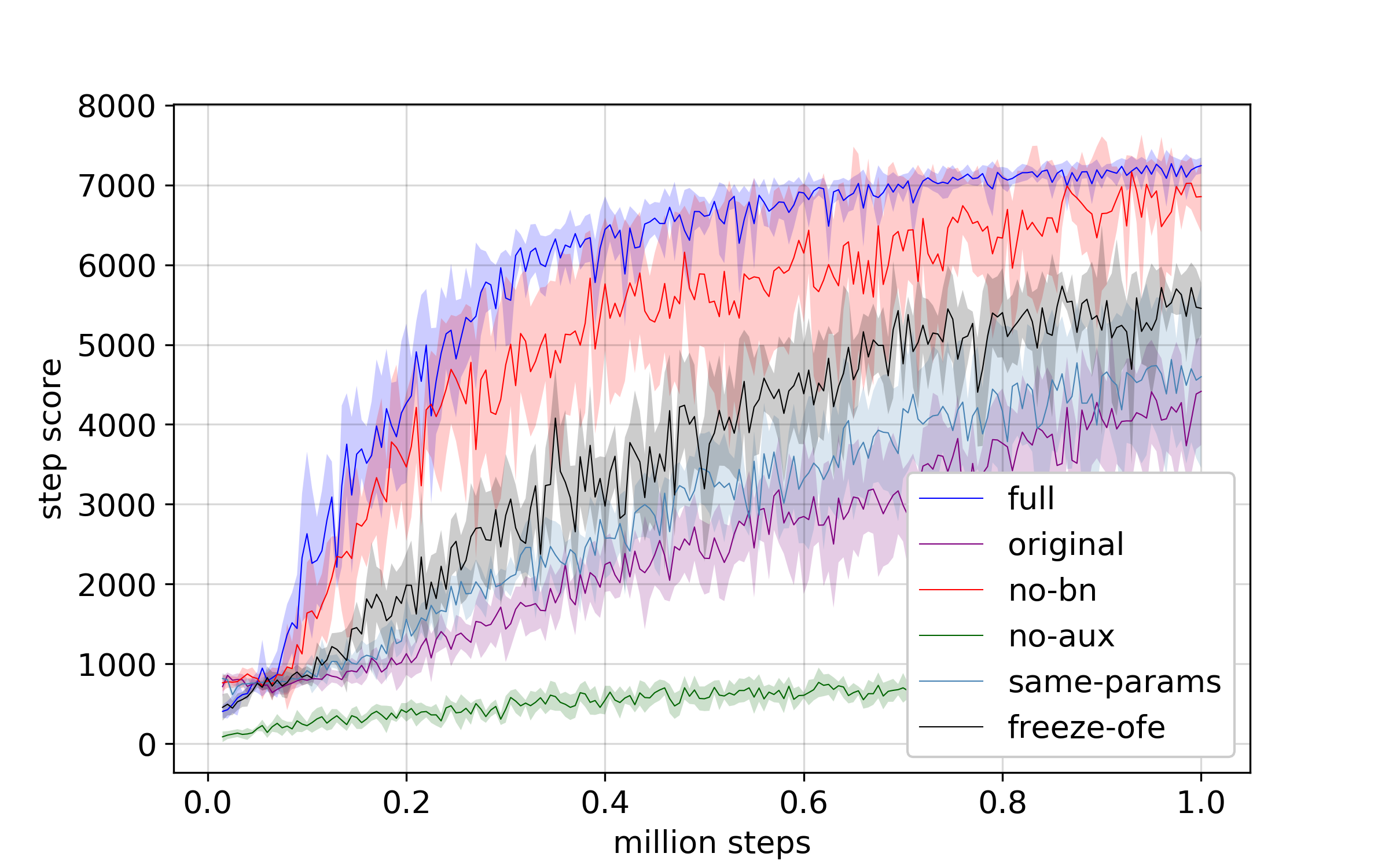
Then, what components of OFENet contributes to the performance gain? We did ablation study with SAC and Ant-v2 environment, and found that we need auxiliary task, batch normalization, and densenet architecture of feature extractor.
So, can increasing input dimensionality improve deep reinforcement learning? Contrary to popular belief that allowing smaller state representation helps in learning complex RL polices, we provide evidence suggesting that representations that are much higher-dimensional than the original observations can significantly accelerate learning of RL agents.
Our proposed OFENet
- achieves state-of-the-art performance on various benchmark tasks involving difficult continuous control problems
- can be easily combined with any RL algorithms because it does not need to tune parameters on RL algorithms. Just put OFENet to bottom of the agent, and replace $o_t,a_t$ with $z_{ o_t},z_{o_t,a_t}$
Check out our paper for more details!