publications
* indicates that authors contributed equally.
2025
- Goal-Conditioned Residual Diffusion PolicyYuki Shirai, Zhengtong Xu, Kei Ota, Diego Romeres, and 1 more authorIn arXiv, 2025
- Learning Pivoting Manipulation with Force and Vision Feedback Using Optimization-based DemonstrationsYuki Shirai, Kei Ota, Devesh K. Jha, and Diego RomeresIn arXiv, 2025
- Analytic Conditions for Efficient Collision Aware Trajectory OptimizationJaitly Akshay, Devesh K. Jha, Kei Ota, and Yuki ShiraiIn IROS, 2025
- Zero-Shot Peg Insertion: Identifying Mating Holes and Estimating SE(2) Poses with Vision-Language ModelsMasaru Yajima, Kei Ota, Asako Kanezaki, and Rei KawakamiIn IROS, 2025
- FlowLoss: Dynamic Flow-Conditioned Loss Strategy for Video Diffusion ModelsKuanting Wu, Kei Ota, and Asako KanezakiIn MVA, 2025
- Modality Selection and Skill Segmentation via Cross-Modality AttentionJiawei Jiang, Kei Ota, Devesh K. Jha, and Asako KanezakiIn MVA, 2025
- Interactive Robot Action Replanning using Multimodal LLM Trained from Human Demonstration VideosChiori Hori, Motonari Kambara, Komei Sugiura, Kei Ota, and 6 more authorsIn ICASSP, 2025
2024
-
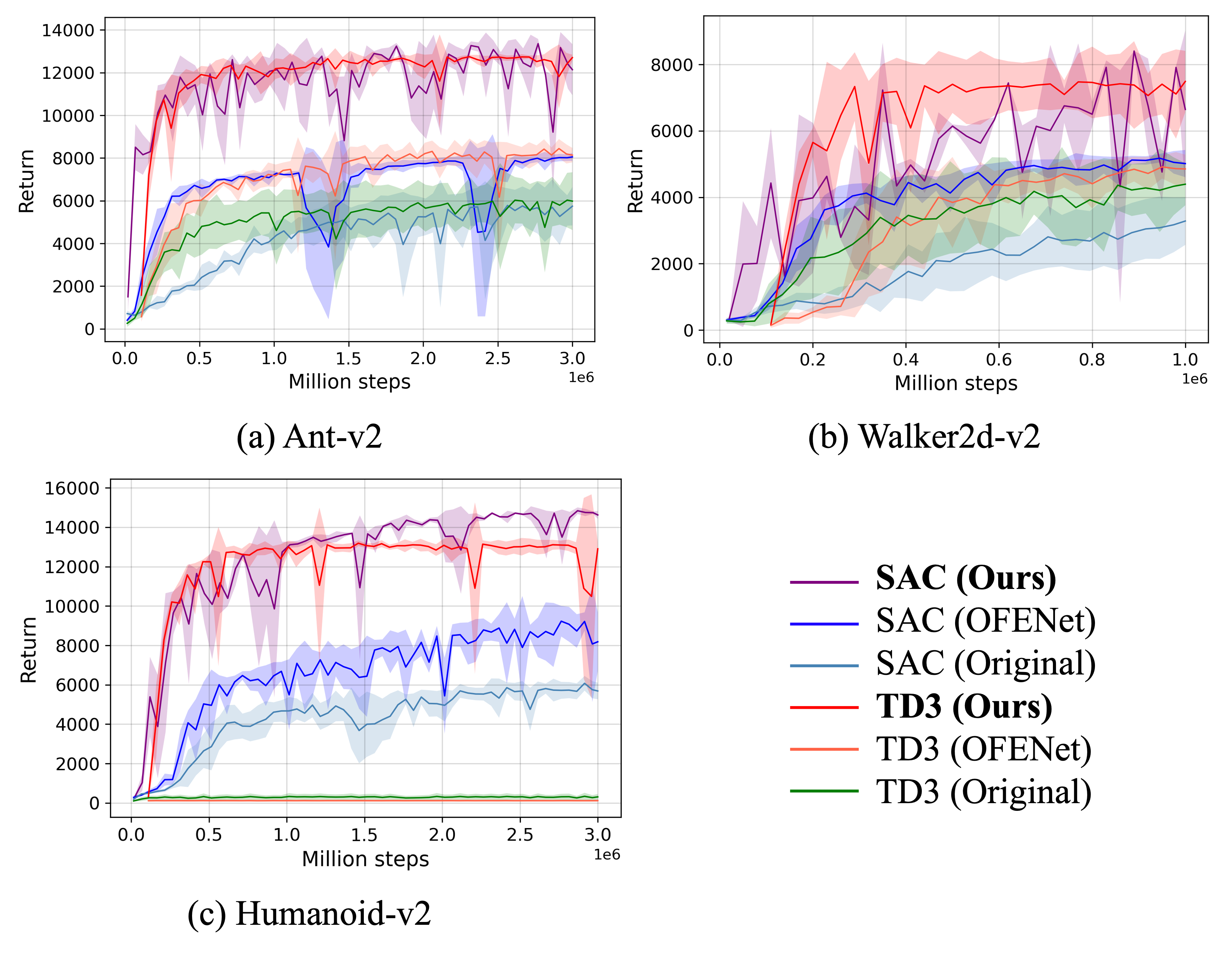 A Framework for Training Larger Networks for Deep Reinforcement LearningKei Ota, Devesh K. Jha, and Asako KanezakiMachine Learning, Jun 2024
A Framework for Training Larger Networks for Deep Reinforcement LearningKei Ota, Devesh K. Jha, and Asako KanezakiMachine Learning, Jun 2024The success of deep learning in computer vision and natural language processing communities can be attributed to the training of very deep neural networks with millions or billions of parameters, which can then be trained with massive amounts of data. However, a similar trend has largely eluded the training of deep reinforcement learning (RL) algorithms where larger networks do not lead to performance improvement. Previous work has shown that this is mostly due to instability during the training of deep RL agents when using larger networks. In this paper, we make an attempt to understand and address the training of larger networks for deep RL. We first show that naively increasing network capacity does not improve performance. Then, we propose a novel method that consists of (1) wider networks with DenseNet connection, (2) decoupling representation learning from the training of RL, and (3) a distributed training method to mitigate overfitting problems. Using this three-fold technique, we show that we can train very large networks that result in significant performance gains. We present several ablation studies to demonstrate the efficacy of the proposed method and some intuitive understanding of the reasons for performance gain. We show that our proposed method outperforms other baseline algorithms on several challenging locomotion tasks.
@article{ota2024aframework, author = {Ota, Kei and Jha, Devesh K. and Kanezaki, Asako}, title = {A Framework for Training Larger Networks for Deep Reinforcement Learning}, journal = {Machine Learning}, year = {2024}, month = jun, day = {05}, issn = {1573-0565}, doi = {10.1007/s10994-024-06547-6}, url = {https://doi.org/10.1007/s10994-024-06547-6}, } -
 Autonomous Robotic Assembly: From Part Singulation to Precise AssemblyIn IROS, Jun 2024
Autonomous Robotic Assembly: From Part Singulation to Precise AssemblyIn IROS, Jun 2024Imagine a robot that can assemble a functional product from the individual parts presented in any configuration to the robot. Designing such a robotic system is a complex problem which presents several open challenges. To bypass these challenges, the current generation of assembly systems is built with a lot of system integration effort to provide the structure and precision necessary for assembly. These systems are mostly responsible for part singulation, part kitting, and part detection, which is accomplished by intelligent system design. In this paper, we present autonomous assembly of a gear box with minimum requirements on structure. The assembly parts are randomly placed in a two-dimensional work environment for the robot. The proposed system makes use of several different manipulation skills such as sliding for grasping, in-hand manipulation, and insertion to assemble the gear box. All these tasks are run in a closed-loop fashion using vision, tactile, and Force-Torque (F/T) sensors. We perform extensive hardware experiments to show the robustness of the proposed methods as well as the overall system. See supplementary video at this [URL](https://www.youtube.com/watch?v=cZ9M1DQ23OI).
@inproceedings{ota2024autonomous, title = {Autonomous Robotic Assembly: From Part Singulation to Precise Assembly}, author = {Ota, Kei and Jha, Devesh K. and Jain, Siddarth and Yerazunis, Bill and Corcodel, Radu and Shukla, Yash and Bronars, Antonia and Romeres, Diego}, booktitle = {IROS}, year = {2024}, } -
 Tactile Estimation of Extrinsic Contact Patch for Stable PlacementIn ICRA, Jun 2024
Tactile Estimation of Extrinsic Contact Patch for Stable PlacementIn ICRA, Jun 2024Precise perception of contact interactions is essential for fine-grained manipulation skills for robots. In this paper, we present the design of feedback skills for robots that must learn to stack complex-shaped objects on top of each other. To design such a system, a robot should be able to reason about the stability of placement from very gentle contact interactions. Our results demonstrate that it is possible to infer the stability of object placement based on tactile readings during contact formation between the object and its environment. In particular, we estimate the contact patch between a grasped object and its environment using force and tactile observations to estimate the stability of the object during a contact formation. The contact patch could be used to estimate the stability of the object upon release of the grasp. The proposed method is demonstrated in various pairs of objects that are used in a very popular board game.
@inproceedings{ota2024tactileestimation, author = {Ota, Kei and Jha, Devesh K. and Jatavallabhula, Krishna Murthy and Kanezaki, Asako and Tenenbaum, Joshua B.}, booktitle = {ICRA}, title = {Tactile Estimation of Extrinsic Contact Patch for Stable Placement}, year = {2024}, volume = {}, number = {}, pages = {13876-13882}, keywords = {Training;Geometry;Force measurement;Stacking;Force;Estimation;Games}, doi = {10.1109/ICRA57147.2024.10611504}, } -
 Robust In-Hand Manipulation with Extrinsic ContactsBoyuan Liang, Kei Ota, Masayoshi Tomizuka, and Devesh K. JhaIn ICRA, Jun 2024
Robust In-Hand Manipulation with Extrinsic ContactsBoyuan Liang, Kei Ota, Masayoshi Tomizuka, and Devesh K. JhaIn ICRA, Jun 2024We present in-hand manipulation tasks where a robot moves an object in grasp, maintains its external contact mode with the environment, and adjusts its in-hand pose simultaneously. The proposed manipulation task leads to complex contact interactions which can be very susceptible to uncertainties in kinematic and physical parameters. Therefore, we propose a robust in-hand manipulation method, which consists of two parts. First, an in-gripper mechanics model that computes a naïve motion cone assuming all parameters are precise. Then, a robust planning method refines the motion cone to maintain desired contact mode regardless of parametric errors. Real-world experiments were conducted to illustrate the accuracy of the mechanics model and the effectiveness of the robust planning framework in the presence of kinematics parameter errors.
@inproceedings{liang2024robust, author = {Liang, Boyuan and Ota, Kei and Tomizuka, Masayoshi and Jha, Devesh K.}, booktitle = {ICRA}, title = {Robust In-Hand Manipulation with Extrinsic Contacts}, year = {2024}, volume = {}, number = {}, pages = {6544-6550}, keywords = {Uncertainty;Accuracy;Computational modeling;Kinematics;Planning;Task analysis;Robots}, doi = {10.1109/ICRA57147.2024.10611664}, } -
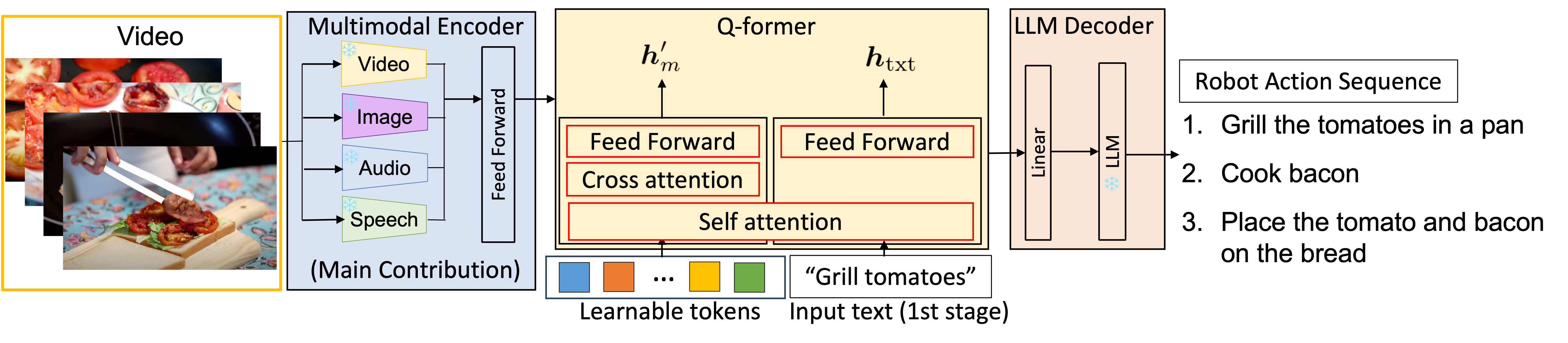 Human Action Understanding-based Robot Planning using Multimodal LLMMotonari Kambara, Chiori Hori, Komei Sugiura, Kei Ota, and 6 more authorsICRA Cooking Robotics Workshop, Jun 2024
Human Action Understanding-based Robot Planning using Multimodal LLMMotonari Kambara, Chiori Hori, Komei Sugiura, Kei Ota, and 6 more authorsICRA Cooking Robotics Workshop, Jun 2024In future smart homes, robots are expected to handle everyday tasks such as cooking, replacing human involvement. Acquiring such skills autonomously for robots is highly challenging. Consequently, existing methods address this issue by collecting data by controlling real robots and training models through supervised learning. However, data collection for long-horizon tasks could be very painful. To solve this challenge, this work focuses on the task of generating action sequences for a robot arm from human videos demonstrating cooking tasks. The quality of generated action sequences by existing methods for this task is often inadequate. This is partly because existing methods do not effectively process each of the input modalities. To address this issue, we propose AVBLIP, a multimodal LLM model for the generation of robot action sequences. Our main contribution is the introduction of a multimodal encoder that allows multiple modalities of video, audio, speech, and text as inputs. This allows the generation of the next action to take into account both the speech information by humans and the audio information generated by the environment. As a result, the proposed method outperforms the baseline method in all standard evaluation metrics.
@article{kambara2024human, title = {Human Action Understanding-based Robot Planning using Multimodal LLM}, author = {Kambara, Motonari and Hori, Chiori and Sugiura, Komei and Ota, Kei and Jha, Devesh K and Khurana, Sameer and Jain, Siddarth and Corcodel, Radu and Romeres, Diego and Roux, Jonathan Le}, journal = {ICRA Cooking Robotics Workshop}, year = {2024}, }
2023
-
 Tactile Pose Feedback for Closed-loop Manipulation TasksKei Ota, Siddarth Jain, Mengchao Zhang , and Devesh K JhaRSS Dexterous Manipulation Workshop, Jun 2023
Tactile Pose Feedback for Closed-loop Manipulation TasksKei Ota, Siddarth Jain, Mengchao Zhang , and Devesh K JhaRSS Dexterous Manipulation Workshop, Jun 2023Current generation manipulation systems operate in an open-loop fashion resulting in poor performance in the presence of disturbances. Robust manipulation requires a robot to compensate for uncertainties and errors arising due to contact interaction during manipulation. Consequently, it is essential that a robot can estimate an object’s state and the relevant contact states so that manipulation can be controlled precisely. However, precise object state estimation is difficult due to occlusions and complex contact interactions during manipulation. This paper presents several different manipulation tasks where a robot may have to perform complex manipulation, which can introduce uncertainty leading to failure. To deal with this problem, we use in-hand pose estimation using vision-based tactile sensors to adjust our plan during manipulation. We present several different analyses for pose estimation using vision as well as tactile sensors to evaluate the importance of different modalities for these precision tasks. We demonstrate that using the proposed approach, we can perform the desired task successfully by incorporating feedback from the tactile pose estimation framework.
@article{ota2023tactilepose, title = {Tactile Pose Feedback for Closed-loop Manipulation Tasks}, author = {Ota, Kei and Jain, Siddarth and Zhang, Mengchao and Jha, Devesh K}, journal = {RSS Dexterous Manipulation Workshop}, year = {2023}, } -
 Tactile-Filter: Interactive Tactile Perception for Part MatingKei Ota , Devesh K Jha, Hsiao-Yu Tung , and Joshua B TenenbaumRSS, Jun 2023
Tactile-Filter: Interactive Tactile Perception for Part MatingKei Ota , Devesh K Jha, Hsiao-Yu Tung , and Joshua B TenenbaumRSS, Jun 2023Humans rely on touch and tactile sensing for a lot of dexterous manipulation tasks. Our tactile sensing provides us with a lot of information regarding contact formations as well as geometric information about objects during any interaction. With this motivation, vision-based tactile sensors are being widely used for various robotic perception and control tasks. In this paper, we present a method for interactive perception using vision-based tactile sensors for a part mating task, where a robot can use tactile sensors and a feedback mechanism using a particle filter to incrementally improve its estimate of objects \cam(pegs and holes) that fit together. To do this, we first train a deep neural network that makes use of tactile images to predict the probabilistic correspondence between arbitrarily shaped objects that fit together. The trained model is used to design a particle filter which is used twofold. First, given one partial (or non-unique) observation of the hole, it incrementally improves the estimate of the correct peg by sampling more tactile observations. Second, it selects the next action for the robot to sample the next touch (and thus image) which results in maximum uncertainty reduction to minimize the number of interactions during the perception task. We evaluate our method on several part-mating tasks \camwith novel objects using a robot equipped with a vision-based tactile sensor. We also show the efficiency of the proposed action selection method against a naive method. See supplementary [video](https://www.youtube.com/watch?v=jMVBg_e3gLw).
@article{ota2023tactile, title = {Tactile-Filter: Interactive Tactile Perception for Part Mating}, author = {Ota, Kei and Jha, Devesh K and Tung, Hsiao-Yu and Tenenbaum, Joshua B}, journal = {RSS}, year = {2023}, } -
 Style-transfer based Speech and Audio-visual Scene Understanding for Robot Action Sequence Acquisition from VideosChiori Hori, Puyuan Peng, David Harwath, Xinyu Liu, and 6 more authorsIn INTERSPEECH, Jun 2023
Style-transfer based Speech and Audio-visual Scene Understanding for Robot Action Sequence Acquisition from VideosChiori Hori, Puyuan Peng, David Harwath, Xinyu Liu, and 6 more authorsIn INTERSPEECH, Jun 2023To realize human-robot collaboration, robots need to execute actions for new tasks according to human instructions given finite prior knowledge. Human experts can share their knowledge of how to perform a task with a robot through multi-modal instructions in their demonstrations, showing a sequence of short-horizon steps to achieve a long-horizon goal. This paper introduces a method for robot action sequence generation from instruction videos using (1) an audio-visual Transformer that converts audio-visual features and instruction speech to a sequence of robot actions called dynamic movement primitives (DMPs) and (2) style-transfer-based training that employs multi-task learning with video captioning and weakly-supervised learning with a semantic classifier to exploit unpaired video-action data. We built a system that accomplishes various cooking actions, where an arm robot executes a DMP sequence acquired from a cooking video using the audio-visual Transformer. Experiments with Epic-Kitchen-100, YouCookII, QuerYD, and in-house instruction video datasets show that the proposed method improves the quality of DMP sequences by 2.3 times the METEOR score obtained with a baseline video-to-action Transformer. The model achieved 32% of the task success rate with the task knowledge of the object.
@inproceedings{hori2023style, author = {Hori, Chiori and Peng, Puyuan and Harwath, David and Liu, Xinyu and Ota, Kei and Jain, Siddarth and Corcodel, Radu and Jha, Devesh and Romeres, Diego and Roux, Jonathan Le}, booktitle = {INTERSPEECH}, title = {Style-transfer based Speech and Audio-visual Scene Understanding for Robot Action Sequence Acquisition from Videos}, year = {2023}, } -
 H-SAUR: Hypothesize, Simulate, Act, Update, and Repeat for Understanding Object Articulations from InteractionsIn ICRA, Jun 2023
H-SAUR: Hypothesize, Simulate, Act, Update, and Repeat for Understanding Object Articulations from InteractionsIn ICRA, Jun 2023The world is filled with articulated objects that are difficult to determine how to use from vision alone, e.g., a door might open inwards or outwards. Humans handle these objects with strategic trial-and-error: first pushing a door then pulling if that doesn’t work. We enable these capabilities in autonomous agents by proposing “Hypothesize, Simulate, Act, Update, and Repeat” (H-SAUR), a probabilistic generative framework that simultaneously generates a distribution of hypotheses about how objects articulate given input observations captures certainty over hypotheses over time, and infer plausible actions for exploration and goal-conditioned manipulation. We compare our model with existing work in manipulating objects after a handful of exploration actions, on the PartNet-Mobility dataset. We further propose a novel PuzzleBoxes benchmark that contains locked boxes that require multiple steps to solve. We show that the proposed model significantly outperforms the current state-of-the-art articulated object manipulation framework, despite using zero training data. We further improve the test-time efficiency of H-SAUR by integrating a learned prior from learning-based vision models.
@inproceedings{ota2023hsaur, author = {Ota, Kei and Tung, Hsiao-Yu and Smith, Kevin A. and Cherian, Anoop and Marks, Tim K. and Sullivan, Alan and Kanezaki, Asako and Tenenbaum, Joshua B.}, booktitle = {ICRA}, title = {H-SAUR: Hypothesize, Simulate, Act, Update, and Repeat for Understanding Object Articulations from Interactions}, year = {2023}, volume = {}, number = {}, pages = {7272-7278}, keywords = {Geometry;Adaptation models;Visualization;Motion segmentation;Training data;Kinematics;Probabilistic logic}, doi = {10.1109/ICRA48891.2023.10160575}, }
2022
-
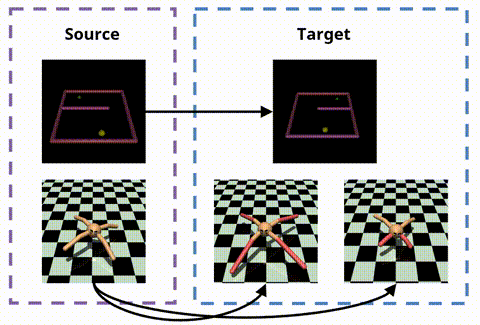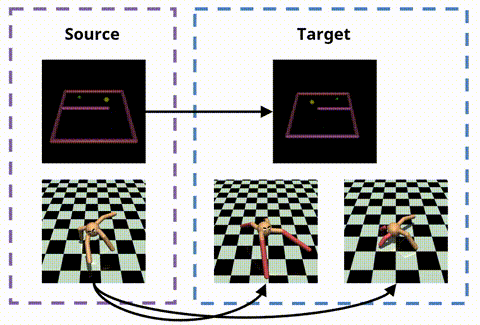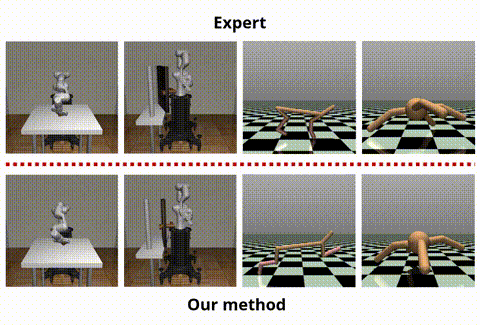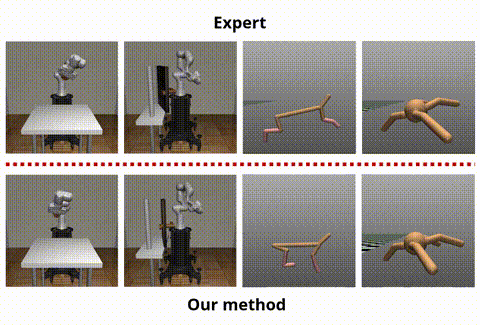 OPIRL: Sample Efficient Off-Policy Inverse Reinforcement Learning via Distribution MatchingHana Hoshino, Kei Ota, Asako Kanezaki, and Rio YokotaIn ICRA, Jun 2022
OPIRL: Sample Efficient Off-Policy Inverse Reinforcement Learning via Distribution MatchingHana Hoshino, Kei Ota, Asako Kanezaki, and Rio YokotaIn ICRA, Jun 2022Inverse Reinforcement Learning (IRL) is attractive in scenarios where reward engineering can be tedious. However, prior IRL algorithms use on-policy transitions, which require intensive sampling from the current policy for stable and optimal performance. This limits IRL applications in the real world, where environment interactions can become highly expensive. To tackle this problem, we present Off-Policy Inverse Reinforcement Learning (OPIRL), which (1) adopts off-policy data distribution instead of on-policy and enables significant reduction of the number of interactions with the environment, (2) learns a reward function that is transferable with high generalization capabilities on changing dynamics, and (3) leverages mode-covering behavior for faster convergence. We demonstrate that our method is considerably more sample efficient and generalizes to novel environments through the experiments. Our method achieves better or comparable results on policy performance baselines with significantly fewer interactions. Furthermore, we empirically show that the recovered reward function generalizes to different tasks where prior arts are prone to fail.
@inproceedings{hoshino2022opirl, author = {Hoshino, Hana and Ota, Kei and Kanezaki, Asako and Yokota, Rio}, booktitle = {ICRA}, title = {OPIRL: Sample Efficient Off-Policy Inverse Reinforcement Learning via Distribution Matching}, year = {2022}, volume = {}, number = {}, pages = {448-454}, keywords = {Training;Automation;Reinforcement learning;Control systems;Behavioral sciences;Usability;Task analysis;Imitation Learning;Transfer Learning;Learning from Demonstration;Inverse Reinforcement Learning}, doi = {10.1109/ICRA46639.2022.9811660}, } -
 Object Memory Transformer for Object Goal NavigationRui Fukushima, Kei Ota, Asako Kanezaki, Yoko Sasaki, and 1 more authorIn ICRA, Jun 2022
Object Memory Transformer for Object Goal NavigationRui Fukushima, Kei Ota, Asako Kanezaki, Yoko Sasaki, and 1 more authorIn ICRA, Jun 2022This paper presents a reinforcement learning method for object goal navigation (ObjNav) where an agent navigates in 3D indoor environments to reach a target object based on long-term observations of objects and scenes. To this end, we propose Object Memory Transformer (OMT) that consists of two key ideas: 1) Object-Scene Memory (OSM) that enables to store long-term scenes and object semantics, and 2) Transformer that attends to salient objects in the sequence of previously observed scenes and objects stored in OSM. This mechanism allows the agent to efficiently navigate in the indoor environment without prior knowledge about the environments, such as topological maps or 3D meshes. To the best of our knowledge, this is the first work that uses a long-term memory of object semantics in a goal-oriented navigation task. Experimental results conducted on the AI2-THOR dataset show that OMT outperforms previous approaches in navigating in unknown environments. In particular, we show that utilizing the long-term object semantics information improves the efficiency of navigation.
@inproceedings{fukushima2022object, author = {Fukushima, Rui and Ota, Kei and Kanezaki, Asako and Sasaki, Yoko and Yoshiyasu, Yusuke}, booktitle = {ICRA}, title = {Object Memory Transformer for Object Goal Navigation}, year = {2022}, volume = {}, number = {}, pages = {11288-11294}, keywords = {Three-dimensional displays;Navigation;Semantics;Reinforcement learning;Benchmark testing;Transformers;Encoding}, doi = {10.1109/ICRA46639.2022.9812027}, }
2021
-
 Data-Efficient Learning for Complex and Real-Time Physical Problem Solving Using Augmented SimulationRAL, Jun 2021
Data-Efficient Learning for Complex and Real-Time Physical Problem Solving Using Augmented SimulationRAL, Jun 2021Humans quickly solve tasks in novel systems with complex dynamics, without requiring much interaction. While deep reinforcement learning algorithms have achieved tremendous success in many complex tasks, these algorithms need a large number of samples to learn meaningful policies. In this paper, we present a task for navigating a marble to the center of a circular maze. While this system is very intuitive and easy for humans to solve, it can be very difficult and inefficient for standard reinforcement learning algorithms to learn meaningful policies. We present a model that learns to move a marble in the complex environment within minutes of interacting with the real system. Learning consists of initializing a physics engine with parameters estimated using data from the real system. The error in the physics engine is then corrected using Gaussian process regression, which is used to model the residual between real observations and physics engine simulations. The physics engine augmented with the residual model is then used to control the marble in the maze environment using a model-predictive feedback over a receding horizon. To the best of our knowledge, this is the first time that a hybrid model consisting of a full physics engine along with a statistical function approximator has been used to control a complex physical system in real-time using nonlinear model-predictive control (NMPC).
@article{ota2021data, author = {Ota, Kei and Jha, Devesh K. and Romeres, Diego and van Baar, Jeroen and Smith, Kevin A. and Semitsu, Takayuki and Oiki, Tomoaki and Sullivan, Alan and Nikovski, Daniel and Tenenbaum, Joshua B.}, journal = {RAL}, title = {Data-Efficient Learning for Complex and Real-Time Physical Problem Solving Using Augmented Simulation}, year = {2021}, volume = {6}, number = {2}, pages = {4241-4248}, doi = {10.1109/LRA.2021.3068887}, }
2020
-
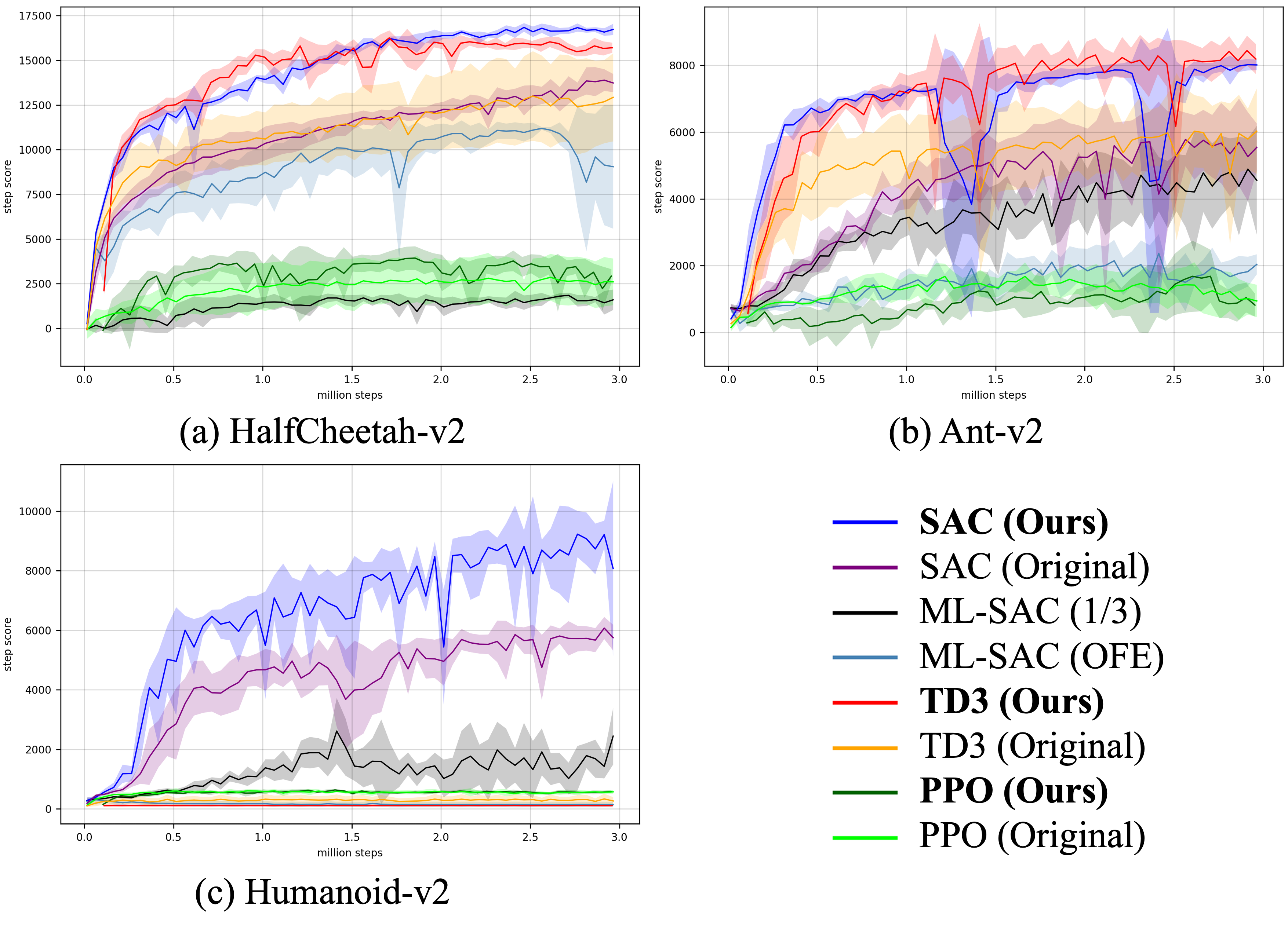 Can Increasing Input Dimensionality Improve Deep Reinforcement Learning?Kei Ota, Tomoaki Oiki, Devesh Jha, Toshisada Mariyama, and 1 more authorIn ICML, 13–18 jul 2020
Can Increasing Input Dimensionality Improve Deep Reinforcement Learning?Kei Ota, Tomoaki Oiki, Devesh Jha, Toshisada Mariyama, and 1 more authorIn ICML, 13–18 jul 2020Deep reinforcement learning (RL) algorithms have recently achieved remarkable successes in various sequential decision making tasks, leveraging advances in methods for training large deep networks. However, these methods usually require large amounts of training data, which is often a big problem for real-world applications. One natural question to ask is whether learning good representations for states and using larger networks helps in learning better policies. In this paper, we try to study if increasing input dimensionality helps improve performance and sample efficiency of model-free deep RL algorithms. To do so, we propose an online feature extractor network (OFENet) that uses neural nets to produce \emphgood representations to be used as inputs to an off-policy RL algorithm. Even though the high dimensionality of input is usually thought to make learning of RL agents more difficult, we show that the RL agents in fact learn more efficiently with the high-dimensional representation than with the lower-dimensional state observations. We believe that stronger feature propagation together with larger networks allows RL agents to learn more complex functions of states and thus improves the sample efficiency. Through numerical experiments, we show that the proposed method achieves much higher sample efficiency and better performance. Codes for the proposed method are available at http://www.merl.com/research/license/OFENet
@inproceedings{ota2020can, title = {Can Increasing Input Dimensionality Improve Deep Reinforcement Learning?}, author = {Ota, Kei and Oiki, Tomoaki and Jha, Devesh and Mariyama, Toshisada and Nikovski, Daniel}, booktitle = {ICML}, pages = {7424--7433}, year = {2020}, editor = {III, Hal Daumé and Singh, Aarti}, volume = {119}, series = {Proceedings of Machine Learning Research}, month = {13--18 Jul}, publisher = {PMLR}, url = {https://proceedings.mlr.press/v119/ota20a.html}, } -
 Deep Reactive Planning in Dynamic EnvironmentsIn CoRL, 16–18 nov 2020
Deep Reactive Planning in Dynamic EnvironmentsIn CoRL, 16–18 nov 2020The main novelty of the proposed approach is that it allows a robot to learn an end-to-end policy which can adapt to changes in the environment during execution. While goal conditioning of policies has been studied in the RL literature, such approaches are not easily extended to settings where the robot’s goal can change during execution. This is something that humans are naturally able to do. However, it is difficult for robots to learn such reflexes (i.e., to naturally respond to dynamic environments), especially when the goal location is not explicitly provided to the robot, and instead needs to be perceived through a vision sensor. In the current work, we present a method that can achieve such behavior by combining traditional kinematic planning, deep learning, and deep reinforcement learning in a synergistic fashion to generalize to arbitrary environments. We demonstrate the proposed approach for several reaching and pick-and-place tasks in simulation, as well as on a real system of a 6-DoF industrial manipulator.
@inproceedings{ota2020deep, title = {Deep Reactive Planning in Dynamic Environments}, author = {Ota, Kei and Jha, Devesh and Onishi, Tadashi and Kanezaki, Asako and Yoshiyasu, Yusuke and Sasaki, Yoko and Mariyama, Toshisada and Nikovski, Daniel}, booktitle = {CoRL}, pages = {1943--1957}, year = {2020}, editor = {Kober, Jens and Ramos, Fabio and Tomlin, Claire}, volume = {155}, series = {Proceedings of Machine Learning Research}, month = {16--18 Nov}, publisher = {PMLR}, url = {https://proceedings.mlr.press/v155/ota21a.html}, } -
 Efficient Exploration in Constrained Environments with Goal-Oriented Reference PathKei Ota, Yoko Sasaki, Devesh K. Jha, Yusuke Yoshiyasu, and 1 more authorIn IROS, 16–18 nov 2020
Efficient Exploration in Constrained Environments with Goal-Oriented Reference PathKei Ota, Yoko Sasaki, Devesh K. Jha, Yusuke Yoshiyasu, and 1 more authorIn IROS, 16–18 nov 2020In this paper, we consider the problem of building learning agents that can efficiently learn to navigate in constrained environments. The main goal is to design agents that can efficiently learn to understand and generalize to different environments using high-dimensional inputs (a 2D map), while following feasible paths that avoid obstacles in obstacle-cluttered environment. To achieve this, we make use of traditional path planning algorithms, supervised learning, and reinforcement learning algorithms in a synergistic way. The key idea is to decouple the navigation problem into planning and control, the former of which is achieved by supervised learning whereas the latter is done by reinforcement learning. Specifically, we train a deep convolutional network that can predict collision-free paths based on a map of the environment– this is then used by an reinforcement learning algorithm to learn to closely follow the path. This allows the trained agent to achieve good generalization while learning faster. We test our proposed method in the recently proposed \textitSafety Gym suite that allows testing of safety-constraints during training of learning agents. We compare our proposed method with existing work and show that our method consistently improves the sample efficiency and generalization capability to novel environments.
@inproceedings{ota2020efficient, author = {Ota, Kei and Sasaki, Yoko and Jha, Devesh K. and Yoshiyasu, Yusuke and Kanezaki, Asako}, booktitle = {IROS}, title = {Efficient Exploration in Constrained Environments with Goal-Oriented Reference Path}, year = {2020}, volume = {}, number = {}, pages = {6061-6068}, keywords = {Training;Navigation;Supervised learning;Reinforcement learning;Prediction algorithms;Path planning;Safety}, doi = {10.1109/IROS45743.2020.9341620}, }
2019
-
 Trajectory Optimization for Unknown Constrained Systems using Reinforcement LearningKei Ota, Devesh K. Jha, Tomoaki Oiki, Mamoru Miura, and 3 more authorsIn IROS, 16–18 nov 2019
Trajectory Optimization for Unknown Constrained Systems using Reinforcement LearningKei Ota, Devesh K. Jha, Tomoaki Oiki, Mamoru Miura, and 3 more authorsIn IROS, 16–18 nov 2019In this paper, we propose a reinforcement learning-based algorithm for trajectory optimization for constrained dynamical systems. This problem is motivated by the fact that for most robotic systems, the dynamics may not always be known. Generating smooth, dynamically feasible trajectories could be difficult for such systems. Using sampling-based algorithms for motion planning may result in trajectories that are prone to undesirable control jumps. However, they can usually provide a good reference trajectory which a model-free reinforcement learning algorithm can then exploit by limiting the search domain and quickly finding a dynamically smooth trajectory. We use this idea to train a reinforcement learning agent to learn a dynamically smooth trajectory in a curriculum learning setting. Furthermore, for generalization, we parameterize the policies with goal locations, so that the agent can be trained for multiple goals simultaneously. We show result in both simulated environments as well as real experiments, for a 6-DoF manipulator arm operated in position-controlled mode to validate the proposed idea. We compare the proposed ideas against a PID controller which is used to track a designed trajectory in configuration space. Our experiments show that our RL agent trained with a reference path outperformed a model-free PID controller of the type commonly used on many robotic platforms for trajectory tracking.
@inproceedings{ota2019trajectory, author = {Ota, Kei and Jha, Devesh K. and Oiki, Tomoaki and Miura, Mamoru and Nammoto, Takashi and Nikovski, Daniel and Mariyama, Toshisada}, booktitle = {IROS}, title = {Trajectory Optimization for Unknown Constrained Systems using Reinforcement Learning}, year = {2019}, volume = {}, number = {}, pages = {3487-3494}, keywords = {}, doi = {10.1109/IROS40897.2019.8968010}, }